前两天托尼不是刚跟大家聊完非常 YES 的 AMD 在台北 Computex 大会上带来的新品嘛。
自古 “ 红蓝出 CP ” ,这不 AMD 刚整完,老冤家英特尔也来了。
是的,就在近日,英特尔带着自己的最新移动端处理器架构也蹦哒着出来了——这才刚过了 8 个月,英特尔又发新架构了,而且看起来是有史以来最大的一次英特尔移动端架构升级。
看来蓝厂也是真的被高通和苹果给卷怕了。
这次的新架构叫 Lunar Lake ,为了方便大家记忆,我们干脆叫它 “ 月亮湖 ” 吧。
留给英特尔的湖( Lake )已经不多了

按英特尔自己的说法是,这次发布的 “ 月亮湖 ” 架构,是专门给笔记本这样的移动设备上的处理器用的,至于台式机处理器用的架构 Arrow Lake ( 我喜欢叫它箭湖 ),会在今年 9 月发布。
所以想自己攒主机的差友们,稍安勿躁,这次我们先看看笔记本上的情况。
这一波 Lunar Lake 的新架构发布活动,托尼有幸参与了英特尔的闭门媒体宣传会,提前了解到了很多新架构的技术细节。
这里插一嘴轻微吐槽一下,英特尔的这个媒体宣传会整整开了五个小时!

好在这五个小时没有白费,整个看下来之后托尼对 “ 月亮湖 ” 这个新架构也有了一个基本的认识。如果让我一句话来评价这个新架构的话,那就是:
英子,你这次真的够清醒,但多少也有点无情了。
大家听我讲完这次 “ 月亮湖 ” 相比上一代 Meteor Lake 的升级点就明白了。
首先我认为英特尔这次最最最最清醒的升级,莫过于终于开始让台积电来给自己代工了!Lunar Lake 用上了台积电 N3B 和台积电 N6 两种工艺。

英特尔近几年,虽然有将 GPU 芯片以及处理器 SoC 当中部分内核交由台积电代工,但是关键的 CPU 核心基本还是由英特尔自己制造。
但是奈何自家的工艺,实在是不争气,就连 CEO 基辛格也不得不承认,台积电拥有更好的制程技术,让台积电代工 “ 月亮湖 ” 的 CPU 核心,是个更好的选择。
台积电的威力如何,不用我多说了吧,夸张一点说简直就是各家厂商处理器芯片的春药。
有了台积电的加成,加上 GPU 升级了新的 Xe2 架构, “ 月亮湖 ” 的图形性能相较于上一代提升了 50% ,显示方面也有了明显的升级;NPU 的 AI 算力更是翻了 4 倍。

除了美美拥抱台积电之外,今年必考项目 AI 算力上, “ 月亮湖 ” 新架构也丝毫不马虎, NPU 算力来到了 48 TOPS 。但不如 AMD 刚发布的 50 TOPS 算力的 Ryzen AI 。
当然啦,就 2 TOPS 的算力差距也不用那么严格,反正这两个难兄难弟总算是满足微软给 AIPC 定下的算力要求( 40 TOPS )了。
这下英特尔终于不用担心闹笑话,可以放心吹 “AIPC” 的概念了。

扯远了,我们继续回来讲英特尔的新架构。
有了 NPU 的 AI 算力升级,再算上 GPU 、 CPU 的 AI 算力, “ 月亮湖 ” 的综合 AI 算力来到了 120 TOPS ,远远超过了上一代的 34 TOPS 。
在获得这么强悍强的性能的同时, “ 月亮湖 ” 整体的功耗相比上一代却下降了 40% 。
不过我得提醒大家,这些都是英特尔给的官方数据,实际表现怎么样,还得等新架构的处理器做到了电脑上,我们体验过才好下定论。
但很明显,英特尔这次更强了也更省电了。
是怎么做到的?除了用上了台积电工艺之外,还有没有别的原因?
这就要提到这次英子另一个很清醒的地方——用上了更加干练的计算单元( Compute Tile )架构,或者说 CPU 架构。
上一代,英子的 CPU 用的还是 6+8 的核心架构,也就是 6 个性能核心( Performance Core )、 8 个能效核心( Efficient Core ),另外在 CPU 之外还会有 2 个低功耗能效核心( Low Power Efficent Core )。

光是这一堆花里胡哨的名字,听起来就头疼了,更何况要把它们都调好。
英特尔自己估计也意识到了这个问题,所以直接在这次的 “ 月亮湖 ” 上大手一挥,把 6 + 8 + 2 一堆乱七八糟的层级给精简了。
直接改用了 4 个性能核心 + 4 个能效核心的架构。

砍核心这个动作,看着是倒吸牙膏的嫌疑,但实际上,新的这 8 个核心要比之前的强得多。
就拿这次的能效核心来说,因为原本比它更擅长轻量任务的低功耗能效核已经被砍了,低负载下的功耗表现就只能指望它了。
而新的能效核心表现非常出色,不管是单线程还是多线程的轻量任务,它都处理得非常好,能效比暴杀上代的低功耗能效核。

同时,原本不该它管的性能,它也表现的非常出色——作为一个专注于低功耗的核心,性能反而要比上一代专门负责性能的核心要强出 2% 。

另外一类核心,性能核,也很争气。新的性能核相较于上一代平均提升 14% 。

意思就是说,砍完核心之后,不但结构更加清晰,更方便软件系统去调度。同时每一类核心本身也变得更强了。
OK ,聊完了新架构在 CPU 上的清醒操作,我们再来看看英特尔这次另一个 “ 清醒 ” 的升级。这次的处理器,他长这样:

看不清没关系,我给你们再放大一下——

你们看到没,英子这回向果子看齐了!
为了用更低的功耗实现更高的性能,英特尔也把原本插在主板上的内存条,做到了处理器里面。
英特尔还给这个做法起了个自己的名字,叫 Memory on Package 。同时提供 16GB 和 32GB ( 双通道 ) LPDDR5X 两种配置。
还行,至少起步不是 8GB 。。。

这个做法好不好,业界内和普通用户一直都在争论。具体怎么评价,还是得从好坏两个方面来分析。
我们先看好处吧。
小学二年级的计算机课上我们已经学过了,电脑的内存是用来暂时存放处理器正在执行的程序和相关数据的。
英特尔这样把内存直接做到了处理器里头,最大的好处当然就是让处理器执行程序、读写数据的效率更高了。
这其实也好理解,每次处理器要用某个数据的时候,再也不用像之前那样,跑老远到外边主板上的内存去拿,自然也就更快了。
与此同时,处理器所需要的功耗也会更低,粗暴一点理解就是每次读写数据不用跑那么远的路了,也就不用耗费那么大的力气了。
那么,代价是什么?
这就要说到英特尔新架构 “ 冷酷无情 ” 的地方了——用户一旦选定了某一个规格的处理器之后,基本上就没法自己更换内存了。
以前给笔记本电脑换内存条的伙伴们,可能还要犹豫一下,是自己把内存条买回来找个视频跟着换呢,还是花点钱去线下维修点让师傅解决。
现在好了,不用纠结了,英特尔把路都堵上了。

以后内存万一出了什么问题,也没法单独修了,只能连着 CPU 一起换掉。
这样搞下来,最难受的当然就是喜欢 DIY 笔记本的小伙伴们,自己动手换内存的乐趣算是彻底被英特尔剥夺了。
建议以后大家买英特尔的本子一定要想清楚,自己对内存大小的需求是多少,毕竟现在是真正的买定离手了,买完后悔想换也换不了。
当然如果你或者你身边的人是华强北老铁,动动手就能给 CPU 开盖、徒手 16G 扩容成 32 G ,那当我没说。
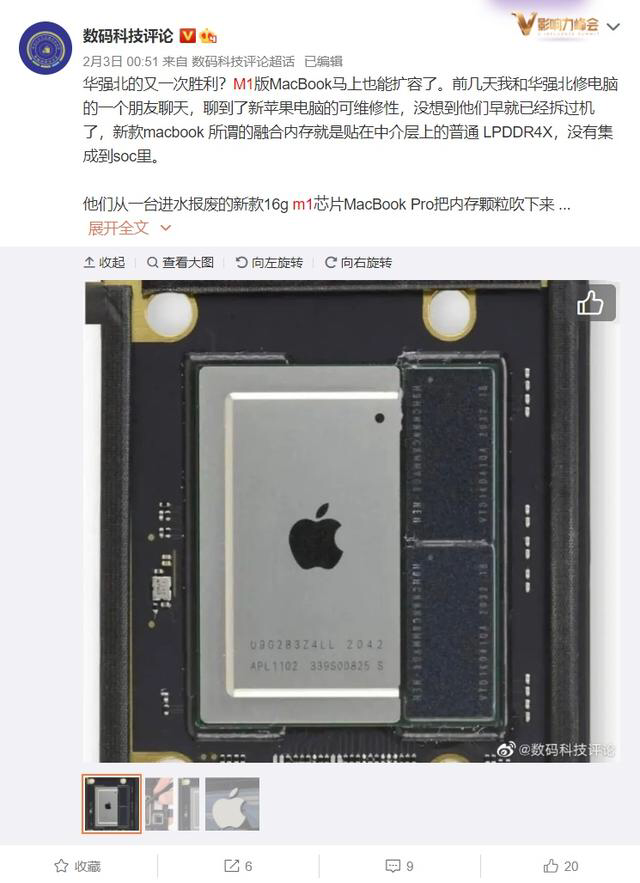
另外这个操作还会带来成本问题。
为了把内存颗粒和处理器的其他模块封装在一个芯片里,英特尔必须给 “ 月亮湖 ” 架构的处理器用上更加先进的封装。
这种内存和处理器放一起的封装,成本比以往要高了不少,英特尔会不会把这个这部分成本转嫁到消费者头上,还得打一个问号。
反正苹果是这么干了,借着内存做到处理器上,工艺、封装等等成本会变高的机会,哐哐地把内存当金子卖。

OK 英特尔的新处理器架构,就给大家聊到这里。
这么盘下来会发现,英特尔这次的升级算得上是亮点多多了。从处理器整体架构到制程工艺,再到性能提升,都可圈可点。
作为英特尔进入 AIPC 时代之后的第二代移动端处理器架构, Lunar Lake 的规划思路也很清晰。没有只顾着大谈特谈 AI 和算力,对于跟普通用户关系更紧密的功耗、续航等等也非常的上心。
而跟隔壁厂跟果子对齐,把内存做到处理器内,这一点也非常的大胆。虽说牺牲掉了一部分用户的需求,但换来更好性能和更低的功耗,我认为还是划算的。
至于换来的这一部分好处有多少能给到笔记本用户,可能还得让子弹再飞一会儿。英特尔把食材做好了,但怎么把菜炒得好吃,就要看终端厂商们怎么去调教了。